Como señalan Chavoshi et al. (2017), una de las principales características que delatan a los bots son patrones temporales de sincronización, pues es muy poco probable que dos usuarios independientes (entre un grupo de \(N\) usuarios activos) hagan \(n\) publicaciones al mismo tiempo en \(m\) segundos. Formalmente, esta probabilidad puede ser definida de la siguiente manera (Chavoshi et al., 2016):
$$p = 1- \frac{M!}{M^N(M-N)!}$$
Donde \(M=m^n\) representa todas las formas posibles en las que un usuario puede hacer \(n\) publicaciones en \(m\) segundos.
Así, en un escenario realista donde \(N = 1\times10^{5}\), \(m = 3600\) y \(n = 10\), \(p\) tiende a cero. Es decir, es practicamente
imposible que dos usuarios (de un total de 100 000 activos), hagan 10 publicaciones al mismo tiempo en el intervalo de una hora.
Incluso, si consideramos que los usuarios en Twitter no actúan de forma completamente independiente, pues pueden reaccionar a
los mismos eventos y noticias de forma similar, la probabilidad de que dos usuarios hagan \(n\) publicaciones a \(\pm{w}\) segundos de un evento relevante en un espacio total de \(m\) segundos sigue siendo extremadamente baja. En este caso, \(p\) queda definida de la siguiente forma:
$$p = 1 – [ (1-q^n)\times(1-2q^n)\times\cdots\times(1-Nq^n) ]$$
Donde \(q\) es la probabilidad de que un usuario reaccione a cualquier otro tweet relevante en \(\pm{w}\) segundos (\(q = 1\) es perfecta sincronía) y \(1-q^n\) la probabilidad de que ninguno de los tweets de un usuario sean publicados en \(\pm{w}\) segundos de distancia del tweet relevante.
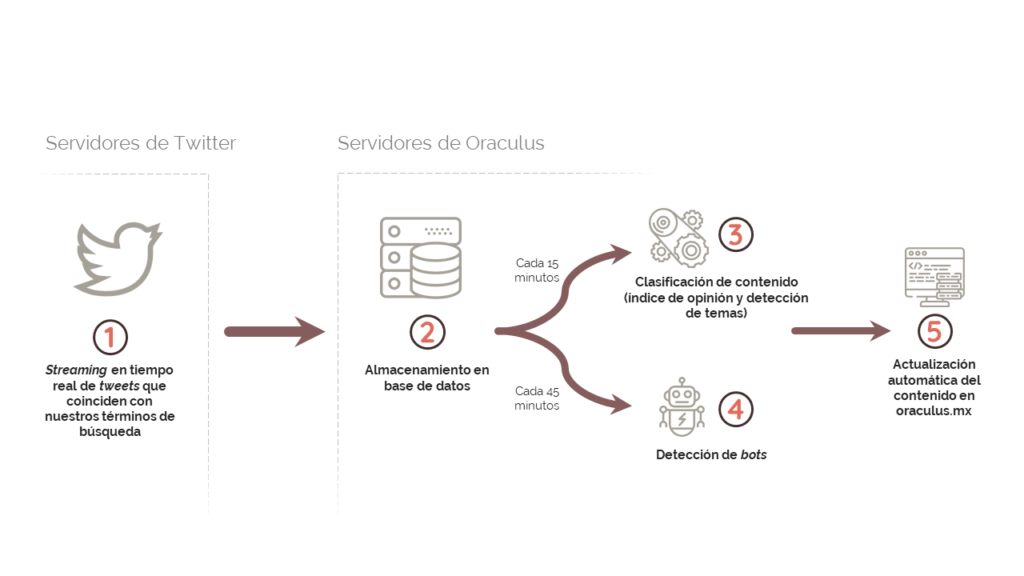
Nuevamente, en un escenario realista donde \(N = 1\times10^{5}\), \(m = 3600\), \(n = 10\) y \(q = 0.25\), \(p\) es próximo a cero. Por esta razón, para detectar cuentas automatizadas en el tráfico de tweets capturado por ORACULUS, implementamos una variación del algortimo propuesto por Chavoshi et al. (2016) en “DeBot: Twitter Bot Detection via Warped Correlation”, el cual busca grupos de cuentas que actúan de manera sincronizada (publicando o compartinedo información) entre el total de cuentas activas. El algoritmo está dividido en dos sistemas: sistema indexador y sistema de validación.
Cada 45 minutos, el sistema indexador construye una señal de actividad para cada usuario activo (una señal de actividad es una serie de tiempo cuya resolución es de un segundo y en la que se marcan las acciones —tweets y retweets— del usuario; se asigna un cero a los momentos de inactividad). Posteriormente, se procesan todas las series de tiempo en una función hash que genera colisiones para aquellas señales de actividad que están correlacionadas en ventanas de hasta 21 segundos. Aquellos usuarios que colisionen más de tres veces en el mismo hash son enviados al sistema de validación para su procesamiento.
El sistema de validación recupera las últimas 200 publicaciones de cada usuario señalado por el sistema indexador y, con base en estos, construye nuevas señales de actividad para cada uno. Posteriormente, calcula una matriz de correlación temporal deformada con todas las señales de actividad usando la siguiente fórmula:
$$wC(x, y) = 1 – \frac{DTW^2(\hat{x}, \hat{y})}{2P}$$
Donde \(DTW^2(\hat{x}, \hat{y})\) es el cuadrado de la deformación temporal dinámica entre las señales de actividad estandarizadas de los usuarios \(x, y\) y \(P\) es el tamaño del vector \(\mathbf{p} = [p_1, p_2,\ldots, p_K]\) calculado por la función \(DTW(\hat{x}, \hat{y})\). Finalmente, el sistema de validación procede a hacer un agrupamiento jerárquico aglomerativo de enlace mínimo en la matriz y clasifica como bots a aquellos grupos de usuarios que presentan una correlación temporal \(wC(x, y)\) mayor o igual a 0.995.
Referencias:
Nikan Chavoshi et al., “DeBot: Twitter Bot Detection via Warped Correlation” (Artículo de ponencia), 16th International Conference on Data Mining, 2016, pp. 817-822.
Nikan Chavoshi et al., “Identifying Correlated Bots in Twitter” (Artículo de ponencia), 8th International Conference on Social Informatics, 2016, pp. 14-21.
Nikan Chavoshi et al., “Temporal Patterns in Bot Activities” (Artículo de ponencia), 26th International Conference on World Wide Web Companion, 2017, pp. 1601-1606.